包装类型
装箱
1 | // 装箱 调用了 Integer.valueOf(2),将int变成了一个Integer对象 |
装箱转换是指将一个值类型隐式地转换成一个object 类型,也就是创建一个object 实例并将这个值复制给这个object。
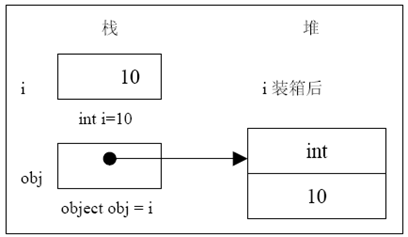
拆箱
拆箱转换是指将一个对象类型显式地转换成一个值类型。
1 | Integer x = 2; //装箱 |
装箱和拆箱会造成相当大的性能损耗,因此尽量应该避免大量的装箱拆箱操作。
缓存池
new Integer()与Integer.Valueof()区别:
- new Integer每次都会新建一个对象
- Integer.Valueof()会复用缓存池中的对象
1 | Integer x = new Integer(123); |
编译器会在自动装箱过程调用 valueOf() 方法,因此多个值相同且值在缓存池范围内的 Integer 实例使用自动装箱来创建,那么就会引用相同的对象。
1 | //a = b |
String
基本类型的变量数据都是存在栈中的,String常量放在常量池里面,String对象放在堆里面。
String常量
String常量存放在常量池里面,常量池中相同的值只有一个。
1 | String s1="hello"; |
- 第一句代码执行后就在常量池中创建了一个值为hello的String对象;
- 第二句执行时,因为常量池中存在hello所以就不再创建新的String对象了。
- 此时该字符串的引用在虚拟机栈里面。
- 因为s1和s2指向的是同一个对象,所以s1==s2
String对象
String对象的本质是一个不可变的char数组。
1 | String a = new String("skj"); |
new String(“skj”)这一步到底做了什么?
- 在字符串常量池里面创建一个对象,就是”skj”,首先会检查常量池里面有没有这个对象”skj”,没有的话在创建并返回对象的引用,有的话就直接返回这个对象的引用。
- 在堆上创建一个对象, new String,String对象的本质就是一个char数组,所以String对象中的char数组指向之前返回对象的引用
- 所以,new String(“skj”)这一句实际上是创建了两个对象,一个在字符串常量池,一个在堆上。
String特性
Strings are constant; their values cannot be changed after they are created. String buffers support mutable strings. Because String objects are immutable they can be shared.
- String是不可变的,因为String的本质是一个final char[],所以String同时又是线程安全的。
- String由final修饰,是不可以继承的。
字符串拼接问题
1 | String str0 = "a"; |
编译成字节码:
1 | public static void main(java.lang.String[]); |
转换成java就是:
1 | String str0 = "a"; |
所以,字符串的拼接主要是通过StringBuilder来实现的。
要注意的是最后还有toString,返回的是一个String对象。
为什么返回的是一个新的String对象呢?
因为String类的char数组是final的,他的指针一旦指向了常量池的某个String,就不可以再改变了.
1 | String str0 = "a"; |
当我们在循环体中进行字符串拼接,在循环体里面,每次拼接都会生成一个StringBuilder的临时对象,那么这个程序片段执行下去就会产生10000个StringBuilder的临时对象,这10000个临时对象都是必要的吗?显然不是,我们可以在循环体外直接创建一个StringBuilder对象,然后在循环体中通过append方法拼接字符串,这样就省下了创建并回收10000个临时对象的消耗。
因此,当我们大量使用字符串拼接的时候,还是使用StringBuilder比较好。
拼接示例
- 使用字符串连接符拼接 : String s2=”se”+”cond”;
- 使用字符串加引用拼接 : String s12=”first”+s2;
- 使用new String(“”)创建 : String s3 = new String(“three”);
- 使用new String(“”)拼接 : String s4 = new String(“fo”)+”ur”;
- 使用new String(“”)拼接 : String s5 = new String(“fo”)+new String(“ur”);

- s2 :这个在编译期间就自动进行了优化的,在常量池中存储一个”second”,并且s2指向它。
- s12 : JVM对于字符串引用,由于在字符串的”+”连接中,有字符串引用存在,而引用的值在程序编译期是无法确定的,即
("first"+s2)无法被编译器优化,只有在程序运行期来动态分配使用StringBuilder连接后的新String对象赋给s12。
(编译器创建一个StringBuilder对象,并调用append()方法,最后调用toString()创建新String对象,以包含修改后的字符串内容),常量池中并没有产生新的字符串常量。 - s3 : 用new String() 创建的字符串不是常量,不能在编译期就确定,所以new String() 创建的字符串不放入常量池中,它们有自己的地址空间。
但是”three”字符串常量在编译期也会被加入到字符串常量池(如果不存在的话) - s4 : 同样不能在编译期确定,但是”fo”和”ur”这两个字符串常量也会添加到字符串常量池中,并且在堆中创建String对象。(字符串常量池并不会存放”four”这个字符串)
- s5 : 原理同s4。
StringBuilder
String的内部实现是一个用final的数组,因此String对象是不可变的,我们每次修改String时,实际上都是new出来了一个新的对象。因此,对于经常进行字符串的修改操作时,String类就需要不断创建新对象,性能极低。StringBuilder内部也是封装的一个字符数组,只不过该数组非final修饰,可以不断修改。所以对于一些经常需要修改字符串的情况,我们应首选StringBuilder。
1 | /** |
append()
1 | public AbstractStringBuilder append(String str) { |
我们可以看到,当StringBuilder添加元素的时候,首先判断char[]是否满了,要是满了,Arrays.copyOf对数组进行扩容(返回的是一个新数组)。最后append的方法返回的this,也就是说,与String不同,他并没有创建一个新的对象,主要原因还是char[]不是final的,是可变的,他就可以转换新的指向。
StringBuilder,StringBuffer,String区别
StringBuffer和StringBuilder都继承了抽象类AbstractStringBuilder,这个抽象类和String一样也定义了char[] value和int count,但是与String类不同的是,它们没有final修饰符。因此得出结论:String、StringBuffer和StringBuilder在本质上都是字符数组,不同的是,在进行连接操作时,String每次返回一个新的String实例,而StringBuffer和StringBuilder的append方法直接返回this,所以这就是为什么在进行大量字符串连接运算时,不推荐使用String,而推荐StringBuffer和StringBuilder。那么,哪种情况使用StringBuffe?哪种情况使用StringBuilder呢?
1 | public StringBuilder append(String str) { |
区别很明显,StringBuffer加了synchronized关键字,是线程安全的。
为何String要设计成不可变的?
- 线程安全
- 字符串常量池的需要。字符串常量池的诞生是为了提升效率和减少内存分配。可以说我们编程有百分之八十的时间在处理字符串,而处理的字符串中有很大概率会出现重复的情况。正因为String的不可变性,常量池很容易被管理和优化。
- 字符串不变,HashCode也不变,便于缓存Hash Code,不需要重复计算HashCode。
intern()
字符串常量池是在编译期间产生的,通过String的intern()也可以在运行时向字符串常量池放入字符串。
When the intern method is invoked, if the pool already contains a string equal to this String object as determined by the equals(Object) method, then the string from the pool is returned. Otherwise, this String object is added to the pool and a reference to this String object is returned.
简单来说就是intern用来返回常量池中的某字符串,如果常量池中已经存在该字符串,则直接返回常量池中该对象的引用。否则,在常量池中加入该对象,然后 返回引用。
1 | public static void main(String[] args) { |
分析一下:
- 先看s3和s4.
String s3 = new String("1") + new String("1");,这样,在字符串常量池创建了一个”1”,并且在堆里也创建了一个对象”11”,但在11中是没有对象的。s3.intern(),先去常量池看看有没有”11”,没有,需要在常量池中存储一份”11”,但是在jdk8中常量池已经转移到堆中了,所以可以直接存储堆中的引用(在jdk6之前,常量池还在perm区,就需要再在常量池中存储一份)。所以,s4实际上是指向堆上对象的引用。 - 再看s1和s2.
String s = new String("1");在常量池内已经存储了1,所以s3.intern()啥也没做,s还是指向堆上的对象,s1指向的是常量池的对象。 - 所以,
String#intern方法时,如果存在堆中的对象,会直接保存对象的引用,而不会重新创建对象。
位运算符
&:按位与
|:按位或
~:异或
^:取反
<<:左移位运算,同理还有右移位运算。
关键字
final
数据:声明数据为常量,一旦初始化之后及不可以改变。
方法:声明方法不可以被重写。
类:声明类不可以被继承。
static
静态变量:类变量,这个变量是属于这个类的,类的所有实例共享,在内存中只存在一份。
静态方法:他在类加载的时候就存在了,它不依赖于任何实例,所以static方法必须实现。
static代码块:在类初始化的时候执行一次。
静态成员不可以访问非静态成员,非静态成员可以访问静态成员和非静态成员。
Object方法
equals() and hashCode()
hashcode()返回的是散列值,equals()用来判断两个对象是否等价,所以在重写equals()方法时一定要先重写hashcode()。等价的对象散列值一定相同,但是散列值相同对象不一定等价。
clone()
需要实现Clonable接口并重写clone()方法,才可以实现拷贝。
1 | public class CloneExample implements Cloneable { |
浅拷贝
拷贝这个对象的时候,只对基本数据类型进行拷贝,而引用数据类型只是进行了引用的传递,这两个对象还是共享的引用数据类型。
1 | public class ShallowCloneExample implements Cloneable { |
深拷贝
在对引用数据类型拷贝的时候,创建了一个新的对象。
1 | public class DeepCloneExample implements Cloneable { |
但是,一般来说,不推荐使用clone,可以使用拷贝构造函数来做。
1 | public class CloneConstructorExample { |
反射
反射的核心是 JVM 在运行时才动态加载类或调用方法/访问属性,它不需要事先(写代码的时候或编译期)知道运行对象是谁。
当我们的程序在运行时,需要动态的加载一些类这些类可能之前用不到所以不用加载到jvm,而是在运行时根据需要才加载,这样的好处对于服务器来说不言而喻。
举个例子我们的项目底层有时是用mysql,有时用oracle,需要动态地根据实际情况加载驱动类,这个时候反射就有用了,假设 com.java.dbtest.myqlConnection,com.java.dbtest.oracleConnection这两个类我们要用,这时候我们的程序就写得比较动态化,通过Class tc = Class.forName(“com.java.dbtest.TestConnection”);通过类的全类名让jvm在服务器中找到并加载这个类,而如果是oracle则传入的参数就变成另一个了。
反射使用
获取class对象
1 | Class s = Class.forName("java.lang.String"); |
创建实例
1 | s.newInstance(); |
获取方法
1 | //获取类或接口生命的方法,但不包括继承的方法 |
获取变量信息
getFiled:访问公有的成员变量getDeclaredField:所有已声明的成员变量,但不能得到其父类的成员变量
调用方法
通过invoke
1 | public class test1 { |
访问私有方法和私有变量
甚至可以通过反射访问私有成员。
只需要setAccessible(true)即可。
1 | private static void modifyPrivateFiled() throws Exception { |
异常
Exception可以通过try catch处理并且使程序恢复。
Error是程序运行时错误,程序会崩溃并且无法恢复。

泛型
泛型就是参数化类型,在泛型使用过程中,操作类型的数据类型被定义为一个参数。
泛型最常见的使用是在容器中,我们给容器添加泛型,这样我们可以把所需要的类型作为参数传递给容器,这样,容器就可以接受所有类型的数据,而且同时只能是一个数据,保证了程序的健壮性。
泛型主要有泛型类,泛型接口,泛型方法。
在编译之后程序会采取去泛型化的措施。也就是说Java中的泛型,只在编译阶段有效。在编译过程中,正确检验泛型结果后,会将泛型的相关信息擦出,并且在对象进入和离开方法的边界处添加类型检查和类型转换的方法。也就是说,泛型信息不会进入到运行时阶段。
泛型类
1 | //此处T可以随便写为任意标识,常见的如T、E、K、V等形式的参数常用于表示泛型 |
泛型接口
1 | public interface Generator<T> { |
泛型方法
1 | class DataHolder<T>{ |
- public 与返回值中间的E声明这是一个泛型方法,只有声明了才可以使用泛型
- 没有声明,只是传参的时候使用了泛型,并不是一个泛型方法。
- 与泛型类的定义一样,此处T可以随便写为任意标识,常见的如T、E、K、V等形式的参数常用于表示泛型。
1 | /** |
泛型擦除
1 | List<String> stringArrayList = new ArrayList<String>(); |
通过上面的例子可以证明,在编译之后程序会采取去泛型化的措施。也就是说Java中的泛型,只在编译阶段有效。在编译过程中,正确检验泛型结果后,会将泛型的相关信息擦出,并且在对象进入和离开方法的边界处添加类型检查和类型转换的方法。也就是说,泛型信息不会进入到运行时阶段
通配符
上界通配符
<? extends T>,只能放置T以及T的子类。下界通配符
<? superT>,只能防止T以及T的父类。无界通配符
<?> ,没有要求。