容器主要包括 Collection 和 Map 两种,Collection 存储着对象的集合,而 Map 存储着键值对(两个对象)的映射表。
Collection
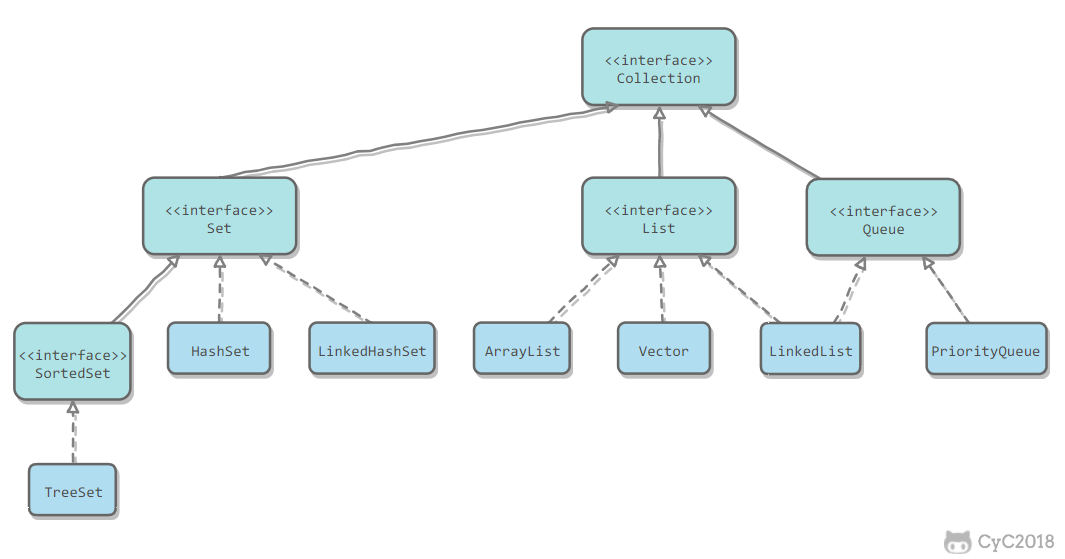
Collection主要分为三类:Set,List,Queue。
Set是无序存储,而且不会存储重复的元素。
Queue是一个队列,只能从一端插入元素,从另一端取出元素。
Map
Map存储的是键值对。
List
ArrayList
ArrayList的底层实现是一个数组,其访问速度比较快,但是插入删除速度比较慢。
1 | //transient表示这个成员不可以被序列化 |
扩容
添加元素时使用 ensureCapacityInternal() 方法来保证容量足够,如果不够时,需要使用 grow() 方法进行扩容,新容量的大小为 oldCapacity + (oldCapacity >> 1),也就是旧容量的 1.5 倍。
扩容操作需要调用 Arrays.copyOf() 把原数组整个复制到新数组中,这个操作代价很高,因此最好在创建 ArrayList 对象时就指定大概的容量大小,减少扩容操作的次数。
1 | private void grow(int minCapacity) { |
删除
1 | public E remove(int index) { |
Vector
它的实现与 ArrayList 类似,但是使用了 synchronized 进行同步,是线程安全的。
1 | public synchronized boolean add(E e) { |
扩容
Vector 的构造函数可以传入 capacityIncrement 参数,它的作用是在扩容时使容量 capacity 增长 capacityIncrement。如果这个参数的值小于等于 0,扩容时每次都令 capacity 为原来的两倍。
1 | private void grow(int minCapacity) { |
与ArrayList不同
- 加了synchronized关键字,是线程安全的。
- Vector 每次扩容请求其大小的 2 倍(也可以通过构造函数设置增长的容量),而 ArrayList 是 1.5 倍。
但是,一般来说,在面对多线程的情况,我们也很少使用Vector,因为效率比较低。
CopyOnWriteArrayList
CopyOnWriteArrayList也是基于写时复制以及读写分离的思想。
当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。对CopyOnWrite容器进行并发的读的时候,不需要加锁,因为当前容器不会添加任何元素。
CopyOnWriteArrayList内部维护了一个数组,而且是volatile的。
1 | /** The array, accessed only via getArray/setArray. */ |
get
1 | public E get(int index) { |
实现非常简单,因为根据写时复制,读取数据的时候数据不会修改,所以肯定是线程安全的。
add
1 | public boolean add(E e) { |
- 需要添加lock,避免出现多个线程写数据。
- 将旧数组拷贝,对新数组进行写操作,操作完成将数组引用指向新数据。
- 实际上核心就是读写其实是在两个不同的容器中,所以就可以进行同时读写。
与读写锁区别
COW与读写锁都使用了读写分离的思想,都可以同时多个线程读。
但是COW读写线程是可以同时的。
缺点
- 数据一致性问题。COW实际上会有读延迟情况的发生。所以,假如对数据实时一致性很高,最好不使用COW。
- 内存问题。COW每次写数据都需要重新拷贝一个数组,假如高并发写或者对象比较大,会造成频繁GC。COW其实是不适用于高并发频繁写的场景。
LinkedList
基于双向链表实现。

Set
Set的核心概念就是集合内所有元素不重复。
HashSet
基于HashMap实现,。
1 | private transient HashMap<E,Object> map; |
意思就是HashSet的集合其实就是HashMap的key的集合,然后HashMap的val默认都是PRESENT。HashMap的定义即是key不重复的集合。使用HashMap实现,这样HashSet就不需要再实现一遍。
1 | //遍历的是HashMap的key |
LinkedHashSet
LinkedHashSet会根据add,remove这些操作的顺序在遍历时返回固定的集合顺序。
TreeSet
基于TreeMap实现。
TreeSet即是一组有次序的集合,如果没有指定排序规则Comparator,则会按照自然排序。