
1 | /** |
海量数据判重问题
假如使用哈希表的话,需要存储上亿条级别的数据,十分浪费空间,尽管查询时间复杂度是O(1).
一般来说,对于这种情况,可以使用布隆过滤器来实现。
比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
布隆过滤器是一个 bit 向量或者说 bit 数组,长这样:
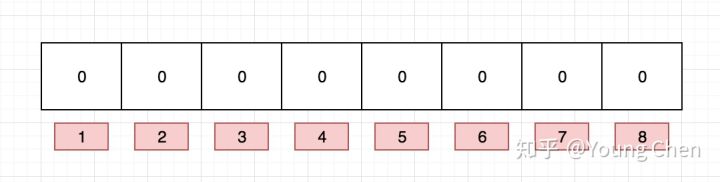
如果我们要映射一个值到布隆过滤器中,我们需要使用多个不同的哈希函数生成多个哈希值,并对每个生成的哈希值指向的 bit 位置 1,例如针对值 “baidu” 和三个不同的哈希函数分别生成了哈希值 1、4、7,则上图转变为:
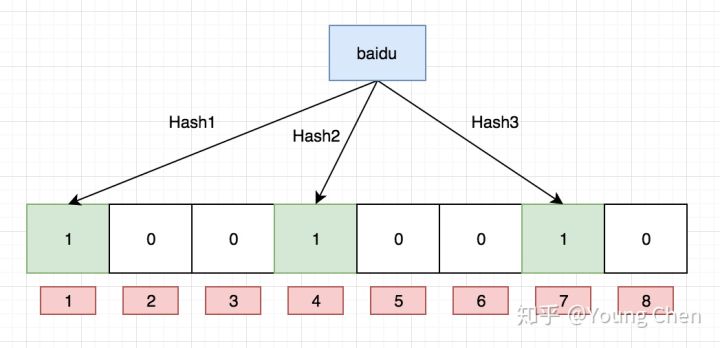
如何判断某一个对象是之前的某一个输入对象呢?
依旧是将该值进行K个哈希函数的计算,求出映射之后的位置是0还是1,假如有0的话,那么该值一定不是之前的某一个输入对象。假如全是1的话,也不一定能保证一定就是之前的某一个输入对象,只是有一定的概率是。
过小的布隆过滤器很快所有的 bit 位均为 1,那么查询任何值都会返回“可能存在”,如何确定过滤器大小?
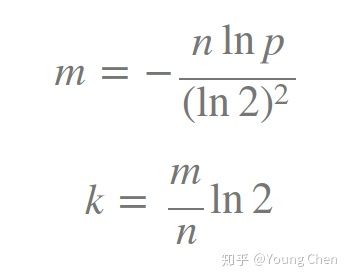
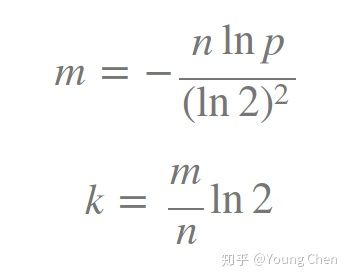
其中,n为元素个数,p为容错率。
一致性哈希
在处理多台服务器负载均衡的时候,传统的hash方式。
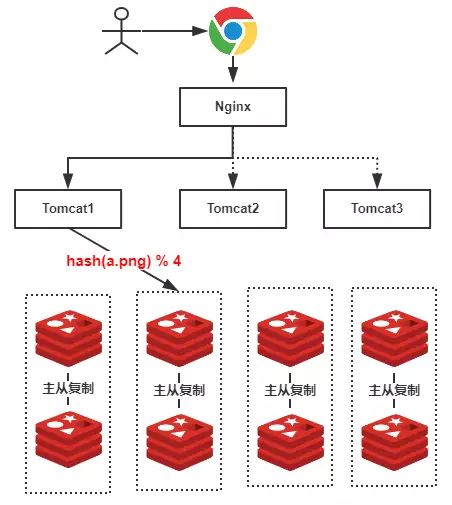
虽然可以达到负载均衡的目的,但是,假如我们需要增加服务器,或者需要移除服务器,就需要重新hash计算之前缓存的所有数据,十分不便。
一致性哈希算法可以解决这个问题,达到高效数据迁移的目的。
一致性Hash算法将整个哈希值空间组织成一个虚拟的圆环,它的取模法不是对服务器数量进行取模,而是对整个哈希值空间。
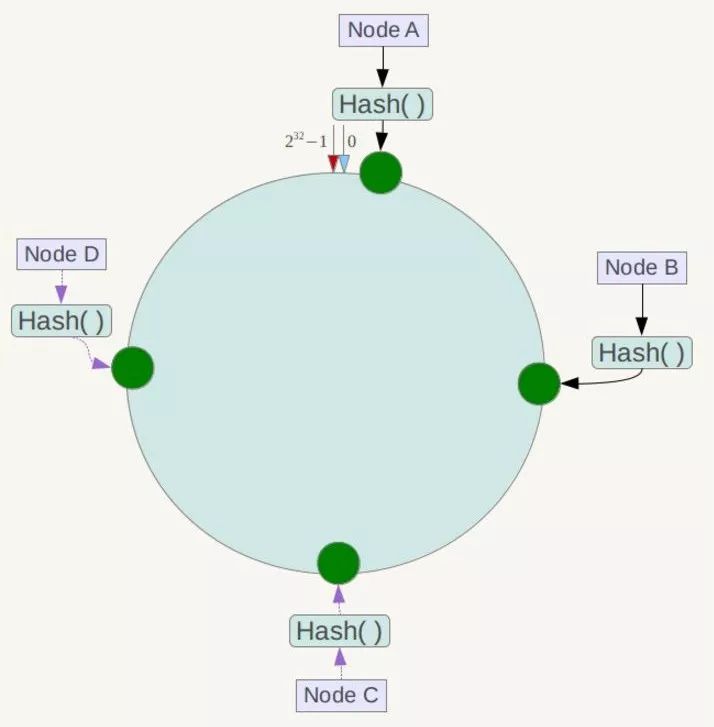
将各个服务器使用Hash进行一个哈希,这样每台机器就能确定其在哈希环上的位置。
接下来使用如下算法定位数据访问到相应服务器:将数据key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器。
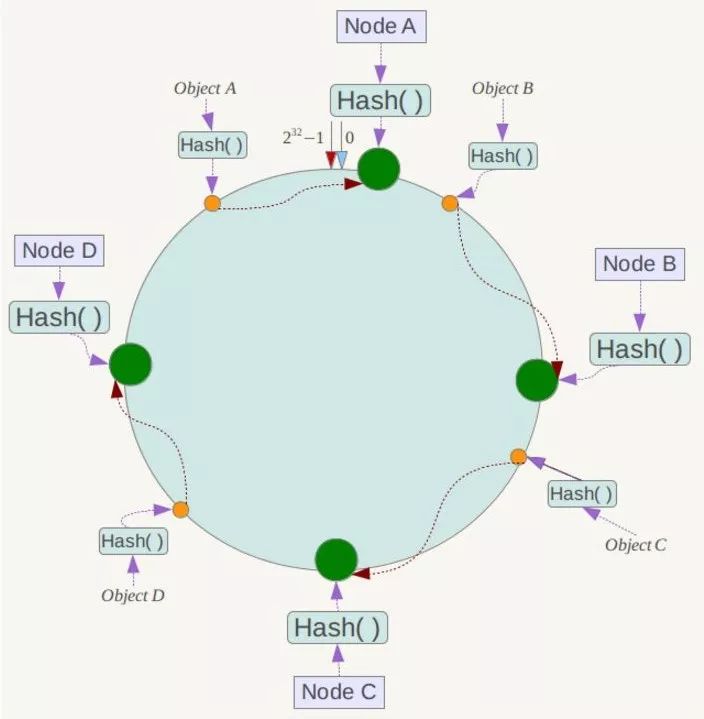
一致性Hash算法的容错性和可扩展性
假如某一个节点宕机,例如C,则只需要将BC之间的数据重新哈希到D上,不需要重哈希全部数据。
增加节点也是,假如BC间添加一个节点,只需要将B与该节点之间的数据重哈希。
一致性Hash算法对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展性。
数据倾斜问题
假如机器比较少,可能造成机器在整个环上分布不均匀。例如:
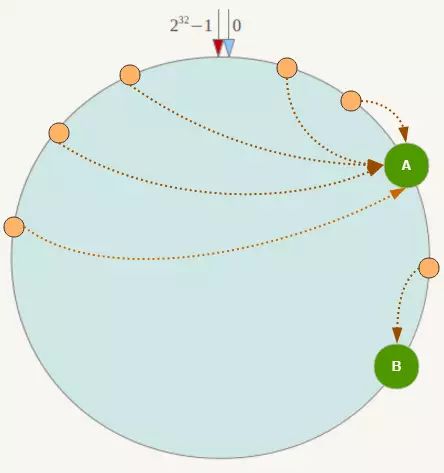
解决该问题可以使用虚拟节点机制。
例如上面的情况,可以为每台服务器计算三个虚拟节点,于是可以分别计算 “Node A#1”、“Node A#2”、“Node A#3”、“Node B#1”、“Node B#2”、“Node B#3”的哈希值,于是形成六个虚拟节点:
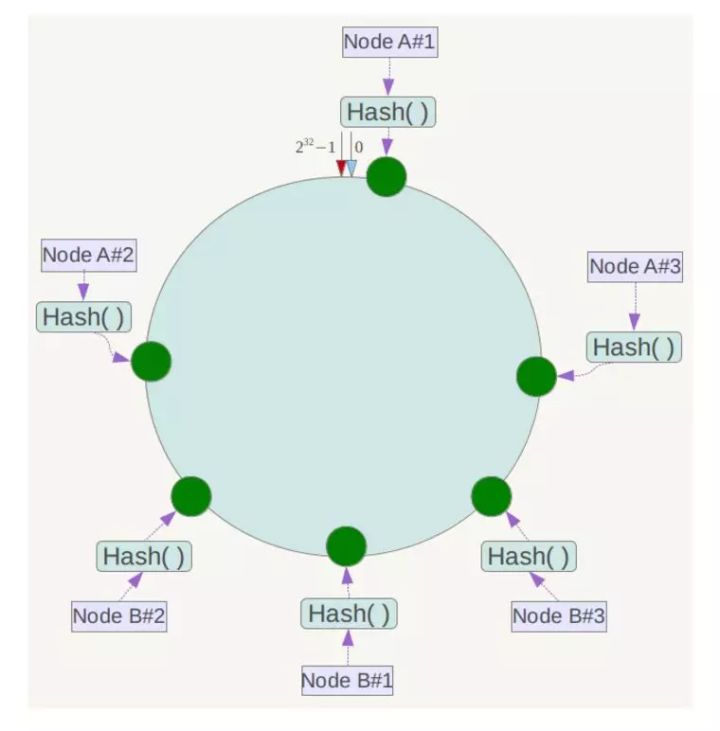
同时数据定位算法不变,只是多了一步虚拟节点到实际节点的映射,例如定位到“Node A#1”、“Node A#2”、“Node A#3”三个虚拟节点的数据均定位到Node A上。这样就解决了服务节点少时数据倾斜的问题。
200. 岛屿数量
1 | public int numIslands(char[][] grid) { |