Kafka是基于发布订阅模式的,采用消费者拉消息的模式,消息可以被重复消费。
一些概念
批量发送
生产者在生产完一条消息后不是直接发送的,而是分批次写入(类似于缓冲),这样可以提高吞吐量。
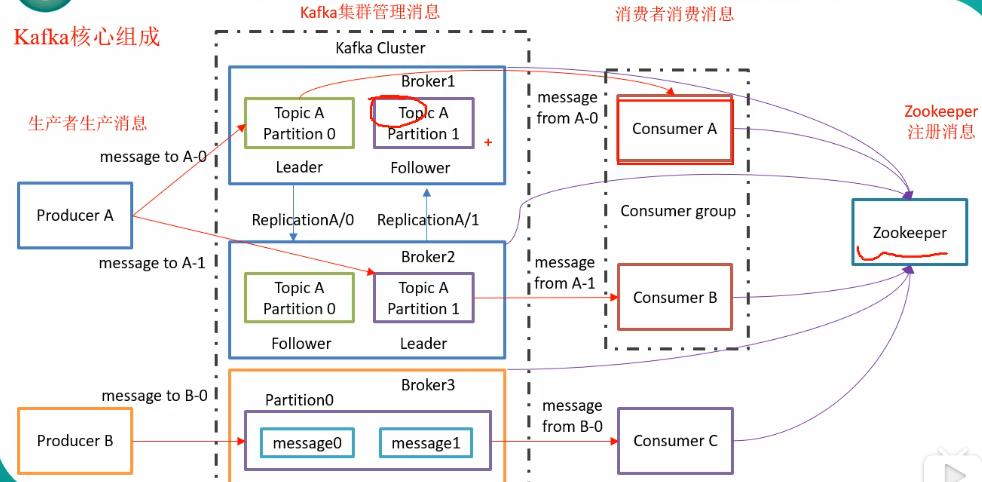
主题(topic)和分区(partition)
kafka通过主题进行分类。一个主题可以包含多个分区,消息以追加的方式写入分区,然后以先入先出的方式顺序读取.但是由于一个主题包含多个分区,因此,不能保证整个主题的消息顺序,只可以保证分区内的消息顺序.kafka是没有索引的。kafka是通过offset来标识消息,即该消息在分区中的偏移量.因此,kafka是几乎不支持随机读写的。
当consumer正常消费消息时,offset将会”线性”的向前驱动,即消息将依次顺序被消费.事实上consumer可以使用任意顺序消费消息,它只需要将offset重置为任意值。
为什么需要分区呢?
主要是为了负载均衡,将消息分散到多个server上.
- 最根本原因是kafka基于文件存储.通过分区,可以,来避免文件尺寸达到单机磁盘的上限,每个partiton都会被当前server(kafka实例)保存;可以将一个topic切分多任意多个partitions,来消息保存/消费的效率.此外越多的partitions意味着可以容纳更多的consumer,有效提升并发消费的能力.
假设我们只有一个分区,那么我们所有的消息都堆积到这一个服务器上.但是,在我们将topic划分为多个分区上,我们可以将分区均匀的分散到多个服务器上,这样,每台服务器压力就会小很多. - 还有一个就是消费者可以并发的读取数据.
生产者
生产者生产消息后,采用顺序写的方式将消息追加写入分区。
流程
- 创建消息:创建一个ProducerRecord对象,主要包括topic,partition,key,value四项,其中patirion和key是可选的.
- 序列化,将ProducerRecord对象序列化.
- 分区选择.若指定分区,直接发送到该分区;若没指定分区,有key,按key哈希计算;若没有key,且没指定分区,采用轮询的方式选择分区。
- 添加进批次里,等到批次满了统一发送.同一批次里的消息topic和partition都应该是相同的.
- 服务器返回响应,消息是否写入成功.
发送消息方式
- 发送即忘记:发送完就不管了。
- 同步发送。
- 异步发送:指定回调函数来对发送异常进行处理。
acks
制定了有多少分区副本收到消息,才算是写入成功。
- acks=0:发送完就不管了,吞吐量高。
- acks=1:首领节点的副本收到消息即可。
- acks=all:所有副本都受到消息。
消费者
高可用性
假如说服务器宕机了怎么办,通过集群来解决。Kafka使用zookeeper来管理集群。多台机器存储数据,当leader宕机了,重新选取一台新的就行了。
多副本冗余
因为kafka是以partition为单位的。其每一个分区都有多个副本,其中,一个leader,其他都是follower,只有leader进行读写。而且多个副本分布在多台机器上,这样,一台服务器宕机,可以通过选举的方式重新选举leader,依然保持是可用的。而且,应该每一个分区的leader分布在不同的机器上,达到负载均衡的目的。例如,机器1存放:leader1,follower2,follower3.机器2存放:follower1,leader2,follower3.机器1存放:follower1,follower2,leader3.这样的话,每一个分区的leader分布在不同的机器上
写数据
写数据的时候,生产者就写 leader,然后 leader 将数据落地写本地磁盘,接着其他 follower 自己主动从 leader 来 pull 数据。一旦 follower 同步好数据了,就会发送 ack 给 leader。具有同步复制以及异步复制两种模式。
读数据
只会从 leader 去读,但是只有当一个消息已经被所有 follower 都同步成功返回 ack 的时候,这个消息才会被消费者读到。
leader follower同步问题
写数据的时候,生产者就写 leader,然后 leader 将数据落地写本地磁盘,接着其他 follower 自己主动从 leader 来 pull 数据。一旦 follower 同步好数据了,就会发送 ack 给 leader。
ISR机制
ISR保存的是与leader数据一致的副本列表,根据副本与leader的交互时间差(每隔XXs会向leader发送一个请求)与信息条数差(follower差leader几条信息)判断是否同步,当超过某个阈值就将其移除ISR。
只有ISR里面的成员才可能被选为leader。当follower又重新追赶上leader之后,将其重新放入ISR。
幂等性
消息不重复消费。
原因
由于提交偏移量可能会有延迟性,会造成Kafka消息重复的问题。
假如采用定时提交,消费者消费完了一部分消息还未提交,突然宕机了。再均衡之后,消费该分区新的消费者会读取原来的偏移量,这样,未提交偏移量的这部分消息会重复消费。
解决
对于每条消息,MQ内部生成一个全局唯一、与业务无关的消息ID:inner-msg-id。当MQ-server接收到消息时,先根据inner-msg-id判断消息是否重复发送,再决定是否将消息落地到DB中。这样,有了这个inner-msg-id作为去重的依据就能保证一条消息只能一次落地到DB。
可靠性
不丢失消息。
生产者
ack=0时,生产者向broker发送消息,发送途中消息丢失。因为ack=0,发送完就不管了,就不会重试发送消息,消息丢失。
ack=all可以解决。
broker
ack==1,假如消息到达broker,而且写入了leader,但此时leader宕机了,而且并没有写入follower,那么选举的新的leader肯定是follower中的,消息会丢失。
ack=all可以解决。
消费者
自动提交的问题。如果在消息处理完成前就提交了offset,那么就有可能造成数据的丢失。
关闭自动提交可以解决。
顺序性
什么导致无序
- 生产者重试。假如发送1,2,2成功了,1由于网络原因丢失,重新发送1,顺序就变味了2,1.
- 分区的问题。假如1,2被发送到了两个不同分区,1所在分区消费的慢,2所在分区消费的快,顺序变为2,1.
- 并行消费的问题。即使1,2在一个分区,且未乱序,可能该分区有两个消费者A,B,A先读取1处理,B后读取2处理,B处理比较快。乱序。
保证局部有序
分区内有序。
例如订单场景,创建,付款,发货需要严格有序。
解决生产者重试问题:每一次确认消息完全到达分区了在发送下一条消息。
解决分区问题:将同一个订单消息发送到同一个分区。可以根据订单号哈希。
解决并行消费问题。分区只有一个消费者。或者对分区加锁。
保证全局有序
不仅仅是分区内有序,而是所有分区都有序。
那就只能之创建一个分区了。
文件存储
同一个topic下有多个不同的 partition,每个 partiton 为一个目录,partition 的名称规则为:topic 名称 + 有序序号。所以,partition是物理概念,topic是逻辑概念。
partition又可以拆分为多个大小相等的segment。拆分为多个segment,一个是因为这样查找效率高;另一个segment为了删除过期的消息而设置的。kafka中消息的写入是直接追加到文件尾部,而消息被消费后也不会被删除,但是我们可以设置一个过期时间进行消息的删除。我们删除消息直接删除segment文件即可。
segment包括一个索引文件,一个数据文件。segment文件的命名:segment文件名为上一个segment文件最后一条消息的offset。
索引文件存储的message在数据文件中的偏移,快速定位message。
文件存储高效原因
分段
采用分段存储的话,因为数据文件以该段中最小的offset命名。这样在查找指定offset的Message的时候,用二分查找就可以定位到该Message在哪个段中。
索引文件
每一个数据文件都有一个索引文件,便于快速寻找消息在段中的位置。
稀疏索引
index file并没有为数据文件中的每条message建立索引,而是采取稀疏索引存储方式,每隔一定字节的数据建立一条索引,它减少了索引文件大小,通过map可以直接内存操作,稀疏索引为数据文件的每个对应message设置一个元数据指针,它比稠密索引节省了更多的存储空间,但查找起来需要消耗更多的时间。
文件读写高效原因
写入优化:顺序写入+Mmap。
读取优化:sendFile零拷贝+读写空中接力
顺序写入
kafka是顺序追加写入的,避免了磁道寻址的时间,顺序写入比随机写入,尤其是机械硬盘效率要大得多。。
MMap
采用MMap来写入数据到磁盘。
传统的文件写入方式是将数据从用户空间转移到内核空间,再由内核空间拷贝到PageCache,最后由操作系统异步刷盘将pageCache中数据落盘。
而MMap省去了用户空间到内核空间的过程,直接将数据写入到pageCache,再由操作系统将pageCache中的数据落盘。
也有一个很明显的缺陷——不可靠,写到mmap中的数据并没有被真正的写到硬盘,操作系统会在程序主动调用flush的时候才把数据真正的写到硬盘。如果在pageCache还未落盘的时候宕机了,数据会丢失。
Kafka提供了一个参数——producer.type来控制是不是主动flush,如果Kafka写入到mmap之后就立即flush然后再返回Producer叫同步(sync);写入mmap之后立即返回Producer不调用flush叫异步(async)。
sendFile零拷贝
消费者在读取消息的时候,使用sendFile。
传统I/O与socket传输:磁盘数据->内核缓冲区->用户空间->内核socket缓冲区->网卡缓存,四次拷贝。
而sendFile直接从内核缓冲区发送到网卡缓存,省掉了两次拷贝。
读写空中接力
- 当写操作发生时,它只是将数据写入Page Cache中,并将该页置上dirty标志。
- 当读操作发生时,它会首先在Page Cache中查找内容,如果有就直接返回了,没有的话就会从磁盘读取文件再写回Page Cache。
- 可见,只要生产者与消费者的速度相差不大,消费者会直接读取之前生产者写入Page Cache的数据,大家在内存里完成接力,根本没有磁盘访问。而比起在内存中维护一份消息数据的传统做法,这既不会重复浪费一倍的内存,Page Cache又不需要GC(可以放心使用大把内存了),而且即使Kafka重启了,Page Cache还依然在。