ThreadLocal是一种空间换时间的方法。
ThreadLocal 适用于每个线程需要自己独立的实例且该实例需要在多个方法中被使用,也即变量在线程间隔离而在方法或类间共享的场景。
ThreadLocal中填充的变量属于这个线程,对于其他线程是不可见的。
ThreadLocal提供了线程的局部变量,每个线程都可以通过set()和get()来对这个局部变量进行操作,但不会和其他线程的局部变量进行冲突,实现了线程的数据隔离。
ThreadLocal是一种空间换时间的方法。
ThreadLocal 适用于每个线程需要自己独立的实例且该实例需要在多个方法中被使用,也即变量在线程间隔离而在方法或类间共享的场景。
ThreadLocal中填充的变量属于这个线程,对于其他线程是不可见的。
ThreadLocal提供了线程的局部变量,每个线程都可以通过set()和get()来对这个局部变量进行操作,但不会和其他线程的局部变量进行冲突,实现了线程的数据隔离。
Queue主要可以分为两类,一类是不阻塞的,一类是阻塞的。非阻塞队列主要有PriorityQueue 和 ConcurrentLinkedQueue。
实现一个线程安全的队列主要有两种方式:阻塞队列(加锁,线程会阻塞;CAS,Locksupport.park)以及非阻塞队列(CAS,线程不会阻塞)。
使用阻塞算法的队列可以用一个锁 (入队和出队用同一把锁)或两个锁(入队和出队用不同的锁)等方式来实现。非阻塞的实现方式则可以使用循环CAS的方式来实现。
非阻塞队列:PriorityQueue(线程不安全) ConcurrentLinkedQueue(线程安全)
比如LinkedList以及ArrayDeque就是双端队列。其中,ArrayQueue是一个用数组实现的双端队列,可以在数组两端进行元素的插入以及删除,所以,这个数组必须是循环数组。LinkedList是基于双向链表的,容量没有限制,可在链表两端进行插入以及删除元素。
ArrayDeque底层是一个数组。
ArrayDeque是一个循环队列。它的实现比较高效,它的思路是这样:引入两个游标,head 和 tail,如果向队列里,插入一个元素,就把 tail 向后移动。如果从队列中删除一个元素,就把head向后移动。
非阻塞队列主要讲一下PriorityQueue以及ConcurrentLinkedQueue。
PriorityQueue又叫做优先级队列,保存队列元素的顺序不是按照及加入队列的顺序,而是按照队列元素的大小进行重新排序。
PriorityQueue内部实现是一个小顶堆,这样保证每次取出来的一定是最小值,他会要求你定义一个Comparable接口。PriorityQueue
PriorityQueue不是线程安全的,在多线程情况下最好使用PriorityBlockingQueue 。
不允许插入 null 元素
无阻塞线程安全的队列,使用CAS+自旋的操作来执行,这样线程不会阻塞,所以叫做非阻塞队列。
如果我们要实现一个线程安全的队列有两种实现方式:一种是使用阻塞算法,另一种是使用非阻塞算法。使用阻塞算法的队列可以用一个锁(入队和出队用同一把锁)或两个锁(入队和出队用不同的锁)等方式来实现,而非阻塞的实现方式则可以使用循环 CAS 的方式来实现。
这些方法实际上是通过调用UNSAFE实例的方法,通过CAS处理是线程安全的。
1 | //更改Node中的数据域item |
阻塞队列(BlockingQueue)被广泛使用在“生产者-消费者”问题中,其原因是BlockingQueue提供了可阻塞的插入和移除的方法。当队列容器已满,生产者线程会被阻塞,直到队列未满;当队列容器为空时,消费者线程会被阻塞,直至队列非空时为止。
生产者消费者问题。 put()以及take()方法
一般来说,使用锁和条件队列实现,线程会阻塞;CAS+LockSupport.park(),线程会阻塞。
ArrayBlockingQueue = ArrayQueue+ReentrantLock+Condition。
所以,一方面,ArrayBlockingQueue使用Array做一个循环队列,另一方面,通过ReentrantLock以及Condition来实现等待唤醒操作。
1 | /** The queued items */ |
源码中可以看出ArrayBlockingQueue内部是采用数组进行数据存储的(属性items),为了保证线程安全,采用的是`ReentrantLock lock`,为了保证可阻塞式的插入删除数据利用的是Condition,当获取数据的消费者线程被阻塞时会将该线程放置到notEmpty等待队列中,当插入数据的生产者线程被阻塞时,会将该线程放置到notFull等待队列中。
1 | public void put(E e) throws InterruptedException { |
1 | public E take() throws InterruptedException { |
底层采用链表来实现。
LinkedBlockingQueue在插入数据和删除数据时分别是由两个不同的lock(takeLock和putLock)来控制线程安全的,因此,也由这两个lock生成了两个对应的condition(notEmpty和notFull)来实现可阻塞的插入和删除数据。
通过takeLock和putLock两个锁来控制生产和消费,互不干扰,不会相互因为独占锁而阻塞。
1 | transient Node<E> head; |
PriorityBlockingQueue是一个底层由数组实现的无界队列,并带有排序功能,同样采用ReentrantLock来控制并发。由于是无界的,所以插入元素时不会阻塞,没有队列满的状态,只有队列为空的状态。通过这两点特征其实可以猜测它应该是有一个独占锁(底层数组)和一个Condition(只通知消费)来实现的。
DelayQueue 是一个支持延时获取元素的阻塞队列, 内部采用优先队列 PriorityQueue 存储元素,同时元素必须实现 Delayed 接口;在创建元素时可以指定多久才可以从队列中获取当前元素,只有在延迟期满时才能从队列中提取元素。
CAS+park.
没有容量的队列。每进行以此put,必须要进行一次take。
CAS+park
LinkedTransferQueue是一个无界的阻塞队列,底层由链表实现。
LinkedBlockingDeque是一个有界的双端队列,底层采用一个双向的链表来实现,在LinkedBlockingQeque的Node实现多了指向前一个节点的变量prev。并发控制上和ArrayBlockingQueue类似,采用单个ReentrantLock来控制并发,这里是因为双端队列头尾都可以消费和生产,所以使用了一个共享锁。
无界队列:PriorityBlockingQueue(有序,数组)、DelayQueue(底层实现为PriorityBlockingQueue,适用于定时任务)和LinkedTransferQueue(链表)。
有界队列:ArrayBlockingQueue(数组)、LinkedBlockingQueue(链表)以及LinkedBlockingDeque(双向链表)。
没有容量:SynchronousQueue
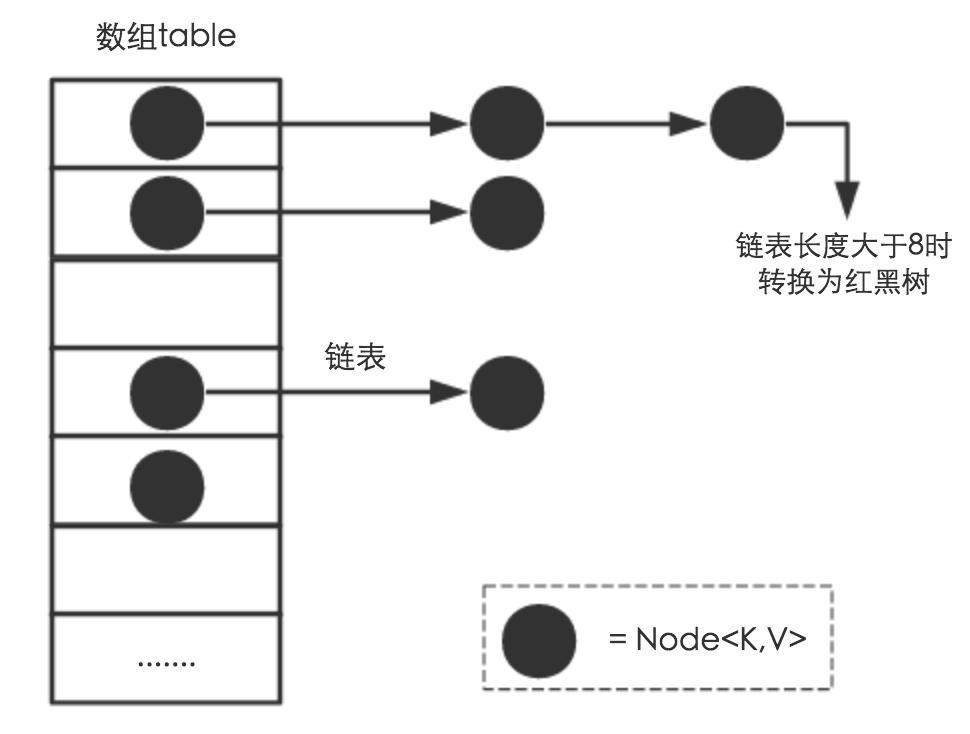
HashMap基于哈希表来实现,哈希表通过哈希计算可以快速地定位到元素的位置,这样插入,删除,查找元素的时间复杂度都是O(1),但是哈希计算有可能会产生哈希冲突,解决的办法包括拉链法,开放地址法等。
HashMap 是基于哈希表的 Map 接口的实现,以 Key-Value 的形式存在,即存储的对象是 Node(同时包含了 Key 和 Value) 。
它根据键的hashCode值存储数据,大多数情况下可以直接定位到它的值,因而具有很快的访问速度,但遍历顺序却是不确定的。 HashMap最多只允许一条记录的键为null,允许多条记录的值为null。HashMap非线程安全。
在存储结构上,HashMap是数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的。
Semaphore叫做信号量,是一种共享锁,当其permit大于0时,线程可以获取锁,当permits小于0时,线程只能等待获取锁,等其他线程释放。
Semophore也有公平锁和非公平锁两种状态。
1 | //公平共享锁尝试获取acquires个信号量 |
CountDownLatch用于协调多个线程的同步,能让一个线程在等待其他线程执行完任务后,再继续执行。内部是通过一个计数器去完成实现。
CountDownLatch是通过一个计数器来实现的,计数器的初始值为线程的数量。每当一个线程完成了自己的任务后,可以调用countDown(),计数器的值就会减1。当计数器值到达0时,它表示所有的线程已经完成了任务,然后在闭锁上等待的线程(使用await()阻塞)就可以恢复执行任务。
一个线程执行需要等待其他线程执行完毕,才能继续执行
1 | public static void main(String[] args) { |
CountDownLatch通过state来表示计数器。
用来控制多个线程互相等待,只有当多个线程都到达时,这些线程才会继续执行。
和 CountdownLatch 相似,都是通过维护计数器来实现的。线程执行 await() 方法之后计数器会减 1,并进行等待,直到计数器为 0,所有调用 await() 方法而在等待的线程才能继续执行。
CyclicBarrier 和 CountdownLatch 的一个区别是,CyclicBarrier 的计数器通过调用 reset() 方法可以循环使用,所以它才叫做循环屏障。
CyclicBarrier 有两个构造函数,其中 parties 指示计数器的初始值,barrierAction 在所有线程都到达屏障的时候会执行一次。

ReentrantReadWriteLock:一个资源能够被多个读线程访问,或者被一个写线程访问,但是不能同时存在读写线程。
读锁是共享锁,可以有多个线程读;而写锁是独占锁,同时只可能有一个线程写。
读锁可以多线程访问,写锁只可以有一个线程访问,我们很容易想到可以使用两个变量来表示读写状态。但是,AQS却只是使用一个state来实现。
1 | static final int SHARED_SHIFT = 16; |
举个例子来看:
这里有两个关键方法sharedCount和exclusiveCount,通过名字可以看出sharedCount是共享锁的数量,exclusiveCount是独占锁的数量。
共享锁通过对c像右位移16位获得,独占锁通过和16位的1与运算获得。
state前十六位代表读锁,后十六位代表写锁。
举个例子,当获取读锁的线程有3个,写锁的线程有1个(当然这是不可能同时有的),state就表示为0000 0000 0000 0011 0000 0000 0000 0001,高16位代表读锁,通过向右位移16位(c >>> SHARED_SHIFT)得倒10进制的3,通过和0000 0000 0000 0000 1111 1111 1111 1111与运算(c & EXCLUSIVE_MASK),获得10进制的1。
由于16位最大全1表示为65535,所以读锁和写锁最多可以获取65535个。
写锁是一把独占锁,同时只可能有一个线程访问,而且不可能与读锁同时存在,所以与ReentrantLock不同的是,WriteLock不仅要判断是否还有其它写线程占用,还要考虑是否还有读线程占用。
读锁是否存在。因为要确保写锁的操作对读锁是可见的。如果在存在读锁的情况下允许获取写锁,那么那些已经获取读锁的其他线程可能就无法感知当前写线程的操作。因此只有等读锁完全释放后,写锁才能够被当前线程所获取,一旦写锁获取了,所有其他读、写线程均会被阻塞。
1 | protected final boolean tryAcquire(int acquires) { |
在获取写锁的时候,如果资源存在读锁,因为可能存在多个不同的线程读,要是修改了线程除了本线程别的线程也感知不到,那么肯定是无法获取写锁的。
但是,在获取读锁的时候, 如果对资源加了写锁,其他线程无法再获得写锁与读锁,但是持有写锁的线程,可以对资源加读锁(锁降级),主要原因是因为在同一个线程内,写锁所做的修改读锁时立即可见的,但是在别的线程内就没有可见性了。
1 | class CachedData { |
ReentrantLock是可重入锁,它实现了Lock接口。
可重入锁就是说同一个线程可以多次申请到该锁。
ReentrantLock有公平锁和非公平锁两种方式。
1 | public void m() { |
使用lock和unlock进行加锁和解锁。
Java有三种编译器i,一种是前端编译器,就是将java文件转变为class文件,这是在编译阶段。一种运行期编译器(JIT编译器),将字节码文件转变为机器码,这是在运行阶段。
编译过程主要分为:
泛型是java语法糖的一种,他的本质是参数化类型。
泛型主要有泛型类,泛型接口,泛型方法。
Java中的泛型只存在于编译阶段,只是用来在编译阶段进行数据校验的作用,在运行时期,泛型就被擦除了,替换为他的原生类型。
1 | List<String> stringArrayList = new ArrayList<String>(); |
在运行阶段,泛型已被擦除,所以,都被替换为ArrayList,是相同的。
个人觉得泛型的作用就是在编译阶段进行语义的审查的作用。
泛型擦除只是从字节码中擦除了,但是元数据中还是保留了泛型信息,所以,我们还是可以通过反射手段取得参数化类型。
1 | Method method = MyClass.class.getMethod("getStringList", null); |
1 | Field field = MyClass.class.getField("stringList"); |
javac 将程序源代码编译,转换成 java 字节码,JVM 通过解释字节码将其翻译成对应的机器指令,逐条读入,逐条解释翻译。很显然,经过解释执行,其执行速度必然会比可执行的二进制字节码程序慢很多。为了提高执行速度,引入了 JIT 技术。
当JVM发现某一段代码执行特别频繁的时候,就会认为他是热点代码,为了提高执行效率,虚拟机就会用过JIT编译器将这些代码编译成机器码,缓存下来。
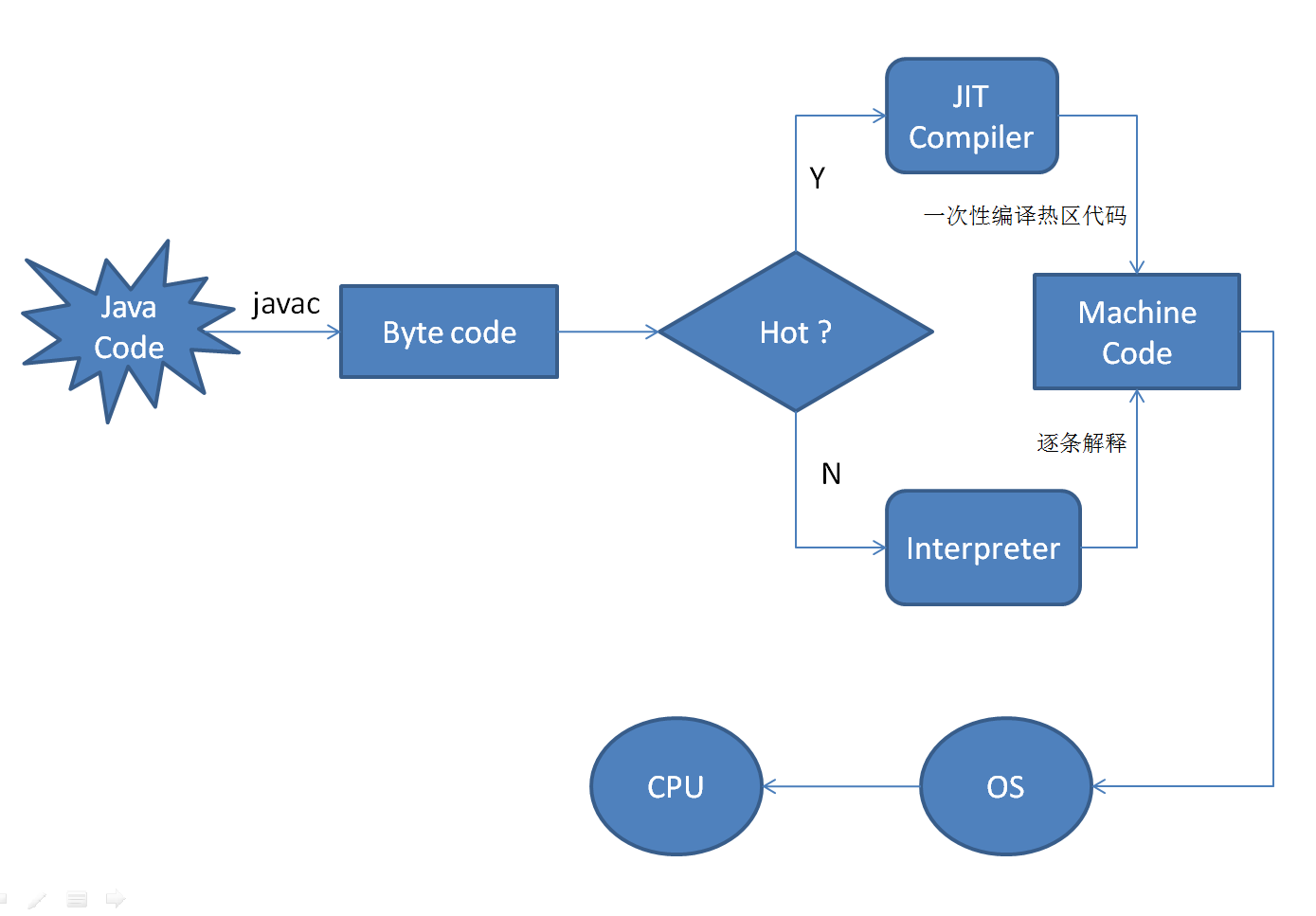
那么,为什么不直接编译呢?
首先,如果这段代码本身在将来只会被执行一次,那么从本质上看,编译就是在浪费精力。因为将代码翻译成 java 字节码相对于编译这段代码并执行代码来说,要快很多。当然,如果一段代码频繁的调用方法,或是一个循环,也就是这段代码被多次执行,那么编译就非常值得了。因此,编译器具有的这种权衡能力会首先执行解释后的代码,然后再去分辨哪些方法会被频繁调用来保证其本身的编译。
JVM是采用解释器与编译器并行的架构。
程序启动时,解释器首先发挥作用,省掉编译的时间,迅速执行。
程序运行后,随着时间的推移,编译器发挥作用,将代码编译成机器码,获取更高执行效率。
HotSpot有两个即时编译器,Client Compiler和Server Compiler,一个注重优化速度,一个注重优化质量。
Client Compiler:编译速度快,优化简单可靠。
Server Compiler:会有一些编译时间比较长的优化。
热点代码有两类。
那么,怎么计数呢?
在HotSpot采用的是第二种,有方法计数器来统计方法调用次数,回边计数器来统计循环代码调用次数。当计数器超过阈值的时候,就会对其进行编译。
如果一个表达式E计算过了,且他的值没有任何变化,那么E再次出现就没必要再次计算,直接用结果。
内联举例:
1 | public int add(int a, int b , int c, int d){ |
内联之后:
1 | public int add(int a, int b , int c, int d){ |
调用一个方法需要建立栈帧等,成本比较大,方法内联可以很好的消除方法调用的成本。
内联条件:
但是,内联并不是这么简单的,我们的程序中大多都是虚方法(不用private,final,static修饰的),那么就会有多态的可能,不知道会不会有子类重写了方法。
JVM团队采用CHA来解决这个问题。
如果一个对象没有逃逸,可以对其做以下优化。